데브코스 TIL - CS 파트4
1. 소프트웨어 개발 프로세스
소프트웨어를 개발하기 위한 필요한 절차나 과정
소프트웨어를 기획/설계/구현/테스트하고 유지보수하는 단계로 구성
✅ 소프트웨어 개발 프로세스 중요성
- 품질향상 (요구사항 분석/테스트 단계에서 오류 발견)
- 일정 준수 (작업 정리 및 진행사항 추적하여 프로젝트 종료일 예측)
- 의사 소통 촉진 (팀 구성원간의 의사소통 촉진)
- 생산성 향상 (불필요한 작업 제거, 개발시간 최적화)
- 고객 만족도 향상 (고객의 요구사항을 명확히 분석하고 적용)
✅ 요구사항 수집 및 분석 단계
매우 중요한 단계
고객과의 요구사항을 개발할 소프트웨어의 기능과 성능, 제약조건을 명확히하는 단계
💡 요구사항 수집
프로젝트 목적과 범위 정의, 고객과 이해관계자의 요구사항을 수집
- 시장 조사, 이해관계자 인터뷰, 설문 조사, 기존 프로젝트나 피드백 문서 분석
💡 요구사항 분류
수집된 요구사항을 기능적 요구사항/비기능적 요구사항으로 분류
- 기능적 요구사항: 소프트웨어가 수행해야할 작업이나 기능
- 비기능적 요구사항: 시스템의 성능이나 보안, 사용성
💡 요구사항 분석
수집된 요구사항을 검토, 모호한 부분 파악
요구사항간의 충돌 해결
비용 시간, 프로젝트 목표 일치도를 분석하여 우선순위 결정
💡 문서화
분석된 요구사항을 바탕으로 명확한 명세서 작성
- 기능 요구사항/비기능 요구사항/제약사항을 상세히 기술
💡 요구사항 검증 및 확인
작성된 명세서가 이해관계자의 요구를 정확히 반영하는지 검증
이해관계자의 피드백을 받아 개선
보통은 단계를 나누어 요구사항을 분석하지 않고 기획자, 개발자, 디자이너가 모여서 요구사항을 논의하고 상세 기획서를 작성하고, 우선순위를 작성한 뒤 피드백을 주고받음
✅ 시스템 설계 단계
요구사항 분석 단계에서 수집된 정보를 바탕으로 시스템 아키텍처와 컴포넌트, 인터페이스, 데이터를 설계
💡 상위설계
시스템의 전체적인 구조와 주요 컴포넌트에 대한 설계
- 시스템 아키텍처 설계
- 모듈화
- 데이터 설계
- 인터페이스 설계
💡 하위설계
상위 설계에서 정의한 각 모듈의 세부 설계
- 데이터베이스 설계
- 클래스 설계 (객체지향을 사용하는 경우)
- 알고리즘 설계
- 에러 처리 및 로깅 방식 정의
💡 핵심 설계 원칙
- 모듈화 - 독립적이고 분리된 모듈로 설계, 시스템의 복잡성을 낮추고 테스트를 용이하게 함
- 캡슐화 - 모듈 내부의 데이터와 구현 세부사항을 외부로부터 숨김, 모듈간의 결합도를 낮춤
- 재사용성 - 범용적으로 모듈화된 컴포넌트로 설계, 개발 효율성을 높이고 일관성을 높임
- 확장성 - 시스템이 향후 변화에 유연하게 대응할 수 있도록 설계, 유지보수를 용이하게 하여 비용을 낮춤
- 응집도와 결합도 - 응집도는 모듈 내부의 요소들의 관련성, 결합도는 모듈간의 상호 의존성, 높은 응집도와 낮은 결합도를 가지도록 설계하는 것이 좋음
- 단순성 - 문제해결과 디버깅을 쉽게하여 전체적인 시스템의 안정성을 향상
💡 소프트웨어 아키텍처
🔍 MVC (Model-View-Control)
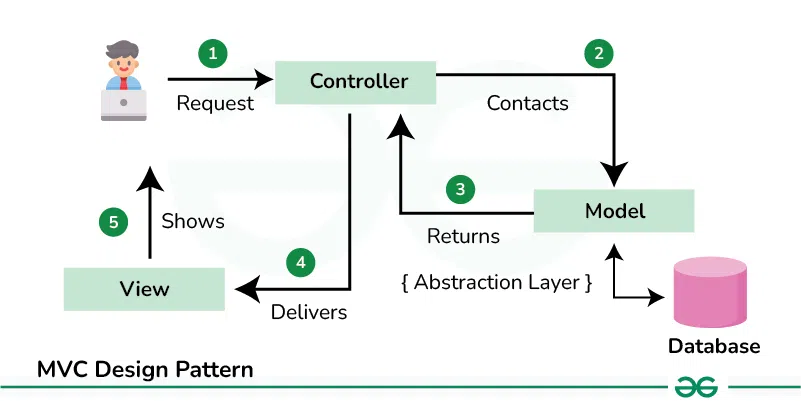
이미지 출처: geeksforgeeks
애플리케이션을 Model,View,Control 서로 다른 역할을 하는 구성요소로 분리하여 개발하는 모델
model과 view는 항상 control 사용하여 상호작용함
각 구성요소가 역할별로 나눠있기 때문에 독립적으로 수정할 수 있으며 유지보수가 용이함
각 구성요소를 재사용할 수 있고, 재사용하기 쉬움
model: 데이터와 비즈니스 로직을 처리, DB에서 데이터를 가져온 후control로 전달view: 사용자에게 정보를 보여주는 역할,control로 받은 데이터로 웹페이지를 생성control: 사용자로부터 받은 요청을 처리,Model-View를 중재
🔍 모놀리식 (Monolithic) 아키텍처
모든 구성요소가 하나의 큰 단위로 개발되고 배포되는 모델
모든 기능이 같은 기술 스택으로 개발됨
장점: 모든 구성요소가 하나의 큰 단위로 개발되기 때문에 개발이 간단하며 및 배포가 쉬우며, 디버깅 및 테스트가 용이
단점: 큰 단위로 개발되기 때문에 개발 속도가 저하되거나 배포가 어려움. 확장하는데 불편함 언어나 프레임워크를 변경할 때에는 전체를 수정해야하기 때문에 시간과 비용이 많이 들기 때문에 기술 채택의 장벽이 있음
🔍 마이크로서비스 (microsevice) 아키텍처
작고 독립적인 서비스의 집합으로 구성하는 모델
특정 기능을 수행하며 독립적으로 개발/운영/배포될 수 있음
장점: 독립적으로 운영되기 때문에 부하가 높아졌을 때 확장이 필요한 서비스만 확장할 수 있기 때문에 확장에 유연하며 배포가 용이. 기술 채택이 유연함
단점: 독립적으로 운영되기 때문에 복잡성이 증가하고, 서비스간의 소통이 네트워크를 사용하기 때문에 네트워크 오버헤드가 발생할 수 있음. 또한 디버깅과 모니터링이 어려움
✅ 구현 단계
설계 단계에서 만들어진 사양을 실행가능한 코드로 변환하는 단계 (요구사항을 충족하는 기능 구현)
💡 주요 활동
- 코딩 - 여러 사람이 함께 코딩하는 경우 표준 규칙을 설정해두는 것이 좋음, 엄격하게 정리해두고 코딩 규칙을 맞게 작성하였는지 체크해주는 라이브러리를 사용하면 좋음
- 통합 - 개별적으로 개발된 코드를 통합하여 전체 시스템이 원활하게 작동되도록 하는 작업
- 단위 테스트 - 개별 단위별로 예상대로 수행하는지 테스트를 작성 (버그 식별)
- 코드 리뷰 - 코드를 검토하여 오류 및 구조 확인
- 리팩토링 - 외부 동작을 변경하지 않고 내부 구성을 변경
- 성능 최적화 - 시스템의 성능을 향상시키기 위한 작업, 자원을 효율적으로 사용하기 위함
- 보안 구현 - 보안 취약점을 찾아 보안 규칙 구현, 암호화
- 문서화 - 개발된 소프트웨어에 대한 기술 문서를 작업 (API, 기술 명세)
- 버전관리 - 버전 관리 시스템을 사용, 변경사항 추척 (브랜치를 사용하여 개발한 뒤 메인 브랜치에 병합하는 방식을 주로 사용)
✅ 테스트 단계
개발된 소프트웨어가 요구사항을 충족하는지, 오류없이 정상적으로 작동하는지 확인하는 단계
미리 버그를 수정함으로써 비용을 절감하며 안정성을 높임
💡 주요 활동
- 테스트 계획 수립
- 테스트 케이스 및 시나리오 작성
- 테스트 환경 설정
- 테스트 실행
- 결함 관리
- 테스트 결과의 평가 및 보고
💡 종류
- 단위 테스트 - 함수나 메소드와 같은 가장 작은 모듈이 제대로 작동하는지 검증
- 통합 테스트 - 여러 모듈들을 통합하며 발생하는 오류를 찾는 테스트 (모듈의 상호작용이 제대로 되었는지)
- 시스템 테스트 - 완성된 시스템이 사용자의 요구사항을 충족하는지 테스트, 실제 사용환경과 유사한 환경에서 테스트
- 인수 테스트 - 사용자나 고객이 직접 테스트를 하여 요구사항을 충족하는지 테스트
- 회귀 테스트 - 소프트웨어를 변경했을 때마다 기존 기능에 영향을 미치지 않는지 확인하는 테스트 (결과 비교)
- 성능 테스트 - 자원 사용량을 확인, 실제 운영환경에서 부하를 견딜 수 있는지 확인
- 보안 테스트 - 시스템의 보안 취약점을 테스트
💡 테스트 자동화
일부 유형의 테스트는 자동화가 어렵기 때문에 QA 담당자가 직접 테스트해야함
- JUnit, Selenium, Cypress, JMeter
✅ 배포 단계
개발이 완료된 소프트웨어를 사용자가 사용할 수 있도록 릴리즈하는 단계
💡 주요 활동
- 릴리즈 준비
- 배포 계획 수립
- 배포 환경 구성
- 소프트웨어 배포
- 파일 복사: HTML,CSS,Javascript파일을 특정 서버에 복사하는 방법
- 가상 서버 이미지 생성: AWS의 경우 EC2 인스턴스를 생성하여 필요한 파일을 설치
- 컨테이너 이미지 생성: 컨테이너 기술을 사용하여 패키징하며 배포하는 방식
- 테스트 및 검증
- 문서화 및 교육
- 운영 및 모니터링 - 성능 지표 수집
💡 배포 전략
- 롤링 업데이트 - 서버를 하나씩 차례대로 업데이트하는 전략, 전체 시스템을 업데이트하는데 오래걸리며 두가지 버전이 공존하는 시간이 있음
- 블루-그린 배포 - 동일한 환경을 두개 준비, 새 버전이 그린환경에 배포된 후에 오류가 발생하지 않으면 블루에서 그린으로 옮김
- 카나리 배포 - 위험을 빠르게 감지할 수 있는 전략, 새로운 버전을 소수의 사용자에게 먼저 제공하고 문제가 없으면 점진적으로 배포하는 전략
💡 지속적 통합 / 지속적 배포
개발 프로세스를 자동화하고 코드 품질을 높일 수 있음
지속적 통합
코드 변경사항을 자주 통합, 개발 초기단계부터 오류를 해결할 수 있음
소스 코드 변경 → 코드 통합 → 자동화된 빌드 → 테스트 실행 → 결과보고
지속적 배포
자동화된 테스트를 통과한 소프트웨어를 고객이 사용가능하도록 자주 업데이트하는 것
CI 프로세스를 통해 빌드 및 테스트 → 자동 배포 → 성능과 안정성 모니터링 → 문제 발생 시 rollback
✅ 유지보수 단계
소프트웨어를 지속적으로 개선하며, 변화하는 환경에 대응하기 위한 단계
💡 주요 활동
- 버그 수정
- 성능 최적화
- 기능 개선 및 추가
- 기술 부채 관리
- 운영 환경 관리
- 보안 업데이트
2. 소프트웨어 개발 방법론
특정 문제에 대한 해결책으로 개발된 방법들
✅ 폭포수 모델 (전통적)
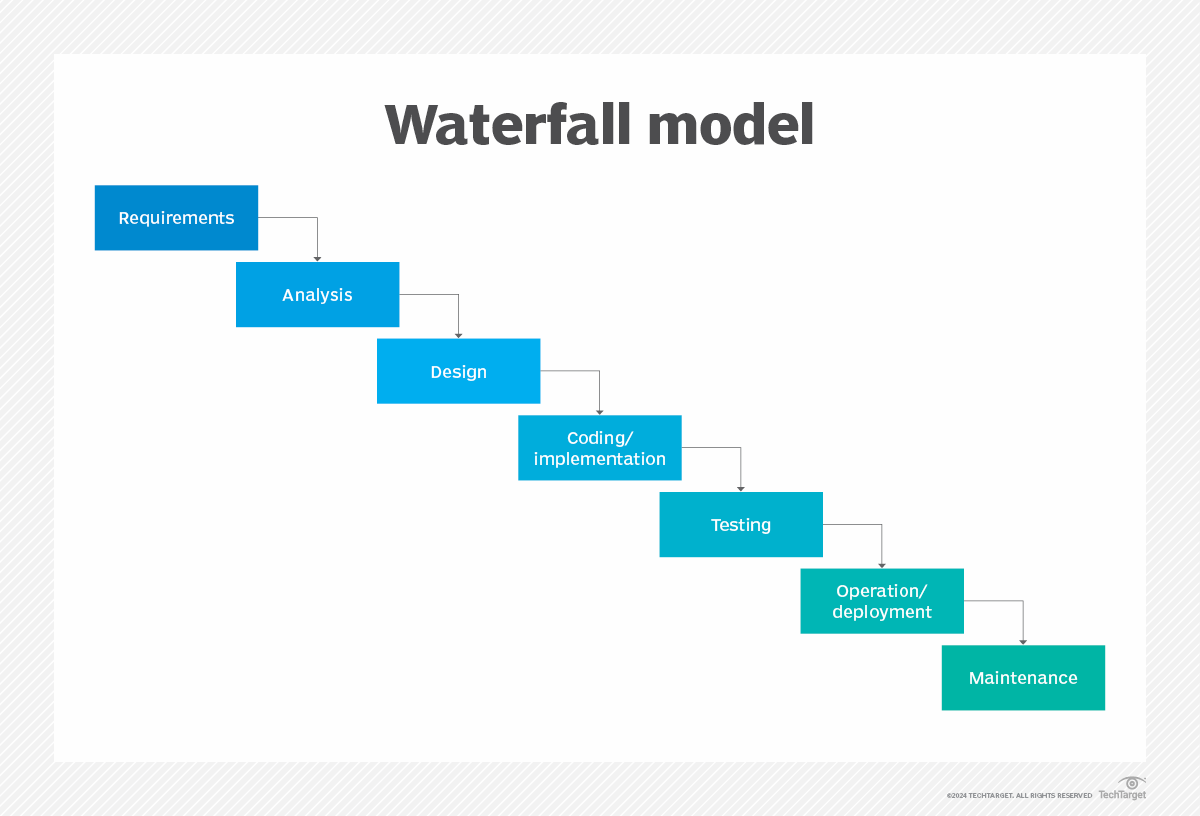 이미지출처: https://www.techtarget.com/searchsoftwarequality/definition/waterfall-model
이미지출처: https://www.techtarget.com/searchsoftwarequality/definition/waterfall-model
소프트웨어 개발 시 단계적으로 개발하는 방법론
프로세스가 단순, 유연성이 떨어짐
요구사항이 잘 정리되고, 요구사항이 변경이 적은 프로젝트에 적합
# 장점:
- 각 단계가 명확하게 정의되어 있어 이해하기 쉬움
- 프로세스 관리가 용이하며, 단계의 진행사항을 쉽게 파악할 수 있음
- 소프트웨어 프로젝트의 비용과 기간을 쉽게 예측할 수 있음
- 모든 단계에서 문서화가 잘 되어 있기 때문에 다양한 문제를 쉽게 찾고 수정할 수 있음
# 단점:
- 구현 단계가 진행되고 있다면 요구사항을 변경하기 어렵기때문에 유연성이 부족함
- 모든 단계가 완료된 후에야 작업 결과물이 고객에게 제공되기 때문에 중간에 가시적인 결과를 볼 수 없음
- 완료된 단계의 작은 변경이나 오류로 인해 전체 소프트웨어 프로젝트가 어려울 수 있음
# 개발 절차:
💡 요구사항 수집 및 분석
고객 및 이해관계자와 소통하여 요구사항을 수집하고 문서화
💡 시스템 설계
시스템의 전반적인 구조와 구성 요소 설계 (UI, 데이터베이스 등)
설계 문서를 작성
💡 구현
설계 문서를 바탕으로 코드 작성
프로그래밍 언어, 프레임워크를 사용하여 요구사항을 만족시키는 소프트웨어 개발
💡 테스팅
구현된 시스템의 품질을 검증하고 오류 확인
결함이 발견되면 결함을 수정하고 다시 테스트
테스트 케이스와 테스트 보고서를 작성
💡 배포
테스트를 통과한 시스템을 실제 운영환경에 배포
💡 유지보수
고객으로 받은 피드백을 바탕으로 변경사항을 적용하고, 오류가 발생하면 수정
보안 업데이트, 성능 개선 등을 수행
✅ 애자일 모델 (현대적)
고객과의 소통을 중요시 여기며 반복적이고 점진적인 개발을 중심으로 함
특징:
- 반복적이고 점진적인 개발 - 스프린트를 통해 제품을 개발, 고객에게 빠른 피드백을 받을 수 있음
- 지속적인 고객 참여
- 팀의 자율성과 자기 조직화 - 공통의 목적을 달성하기 위해 협력함
- 지속적인 개선과 적응 - 정기적인 회고를 통해 개선방안과 해결책을 논의함
💡 스크럼
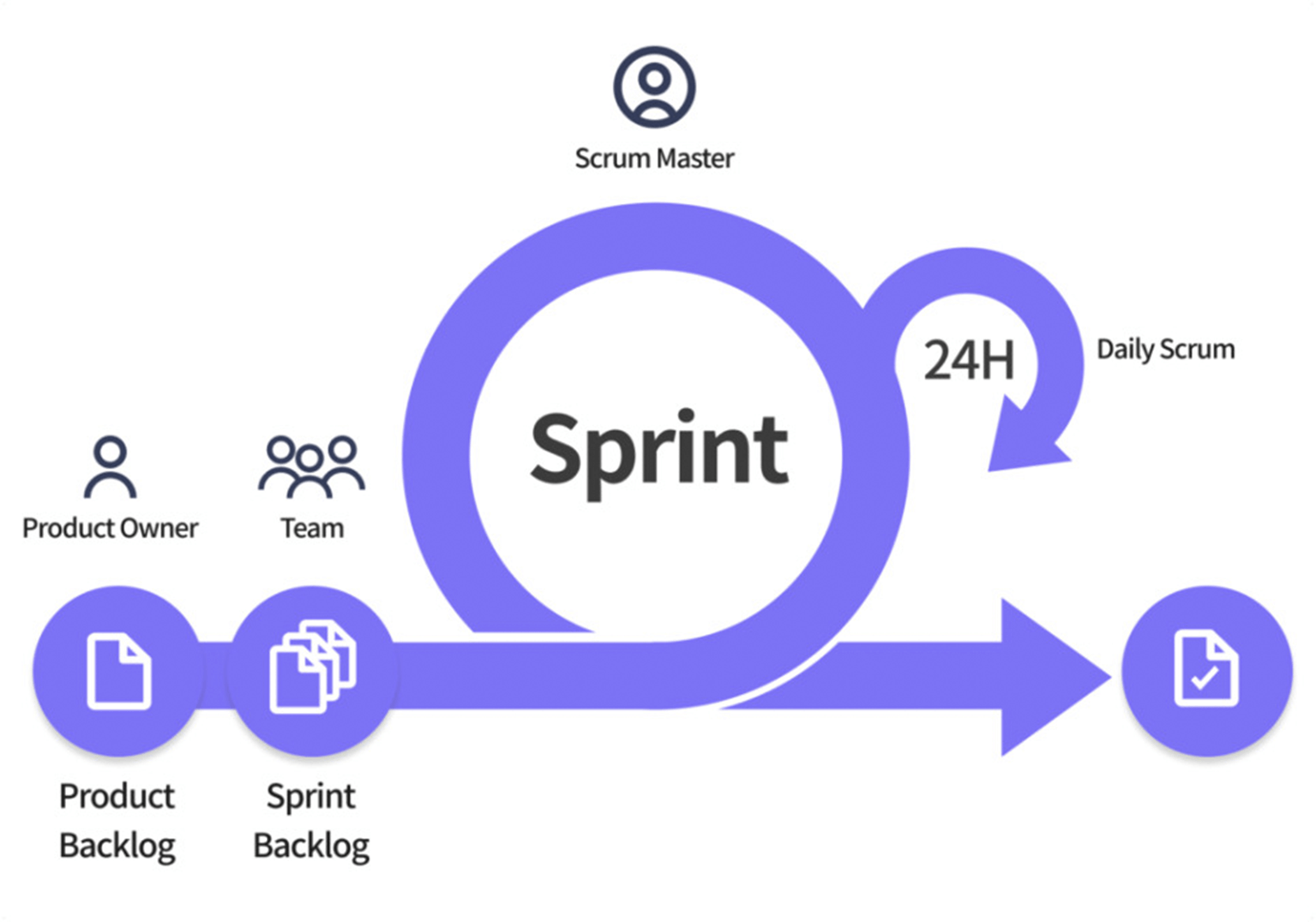 이미지 출처: https://boardmix.com/kr/reviews/agile-scrum-vs-agile-kanban/
이미지 출처: https://boardmix.com/kr/reviews/agile-scrum-vs-agile-kanban/
가장 널리 사용되는 애자일 방법론
스프린트를 반복, 마감기한이 정해져있고 매일 스크럼 미팅을 진행
💡 칸반
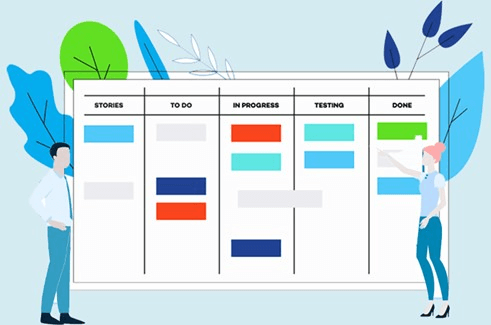 이미지 출처: https://boardmix.com/kr/reviews/agile-scrum-vs-agile-kanban/
이미지 출처: https://boardmix.com/kr/reviews/agile-scrum-vs-agile-kanban/
필요한 작업 목록을 우선순위에 따라 나누고 프로젝트의 진척도를 확인
💡 XP (Extreme Programming)
개발 실천 방법에 초점을 맞춘 방법론
- 페어프로그래밍
- 테스트 주도 개발 (TDD)
- 지속적 통합 (CI)
- 짧은 릴리스 주기
3. 웹 서비스 아키텍처

이미지 출처: https://medium.com/storyblocks-engineering/web-architecture-101-a3224e126947
프론트엔드, 백엔드, 데이터베이스가 가장 중요
✅ 클라이언트-서버 모델
컴퓨터 네트워크 아키텍처 중 하나
- 클라이언트 - 서비스를 요청하는 주체
- 서버 - 네트워크를 통해 클라이언트 요청에 응답해 데이터나 응답을하는 주체
장점: 역할 분담, 중앙 집중화 (일관성 유지), 확장성, 보안성
단점: 단일 장애점 (서버에 오류가 생기면 모든 클라이언트가 오류를 겪음), 서버 부하, 관리 복잡성
💡 작동원리
- 클라이언트 - 서버에 특정 자원이나 서비스에 대한 요청을 보냄
- 서버 - 요청을 처리한 뒤 필요한 데이터나 클라이언트에게 응답
💡 클라이언트의 역할
사용자에게 직접적인 인터페이스 제공, 서비스 요청, 입력 데이터 처리, 서버로부터 응답 수신 및 처리
💡 서버의 역할
컨텐츠의 제공, 데이터의 관리와 저장, 보안, 동시 요청 처리, 확장성 및 안정성 제공
✅ 프론트엔드
사용자에게 직접적인 인터페이스 만듬, 사용자의 요청을 백엔드로 전달, 응답받은 결과를 사용자에게 보여줌
💡 구성요소
HTML, CSS, Javascript
💡 프로그래밍 언어 및 프레임워크
- vanilla javascript
- jQuery
- React, Vue, Svelte
💡 반응형 프로그래밍 패러다임
데이터 스트림과 변경사항 전파를 중심으로 하는 선언적 프로그래밍 패러다임
데이터의 변화가 자동으로 컴포넌트로 전달되어 UI를 업데이트를 하는 방식으로 사용됨
✅ 백엔드
💡 주요 역할
- 데이터 처리 및 관리 (조회/수정/삭제)
- 비즈니스 로직 구현
- API 제공
- 서버 관리
- 보안
💡 프로그래밍 언어 및 프레임워크
- Java / Spring
- Python / Django
- Node.js / Express
- Ruby on Rails
- PHP
✅ 데이터베이스
데이터를 저장하고 관리하는 역할
💡 관계형 데이터베이스
테이블 형태로 데이터를 저장하고 관리
- MySQL, PostgreSQL, Oracle (대규모 엔터프라이즈 환경에서 주로 사용), SQL Server
💡 비관계형 데이터베이스
document, key-value, Graph와 같은 다양한 형태로 저장하고 관리
- 사용자 세션 관리, 실시간 분석 및 대용량 처리할 때 주로 사용
- MongoDB, Cassandra, Redis, DynamoDB
✅ 캐싱
자주 사용되는 데이터나 계산 결과를 미리 저장해두고 동일한 요청이 왔을 때 빠르게 응답할 수 있도록 해주는 기술
key-value 형태로 저장
장점: 응답시간 단축, 서버 부하 감소, 네트워크 부하 감소
단점: 만료된 데이터, 복잡성 증가
💡 종류
- 객체 캐싱 - 사용자 세션 (로그인 정보 캐싱), 뉴스 기사, 장바구니
- (전체/일부) 페이지 캐싱 - 뉴스 메인 페이지, 게시글 페이지
- 브라우저 캐싱
💡 캐시 무효화 전략
- 명시적 무효화 - 데이터베이스 등 원본 데이터가 변경되었을 때 캐시된 데이터를 업데이트하거나 제거 (실시간 데이터 처리에 효율)
- 만료시간기반 무효화 - 캐시된 객체에 TTL을 설정하여 일정 시간 지나면 해당 객체를 무효화
- 버전 기반 무효화 - 캐시 데이터에 버전 번호를 할당하여 무효화를 관리
✅ 로깅
발생하는 이벤트를 저장하고 관리하는 것
목적: 디버깅, 성능 모니터링, 보안, 감사(Audit)
💡 고려사항
- 로그 레벨:
- debug - 상세한 정보를 기록
- info - 정보성 메세지 기록
- warn - 예상치 못한 상황 기록 (주의사항)
- error - 실행중에 발생한 오류 메세지 기록
- fatal - 치명적인 오류 (비정상 종료, 데이터 손상 등)
- 로그 포맷
- 로그 로테이션
- 로그 보안
- 로그 관리 도구 - ELK 스택, CloudWatch Logs
✅ 잡서버 (Job Server)
비동기적으로 처리
장점: 응답 속도 향상, 확장성, 작업 실패 처리 및 재시도
💡 동작
- Job 생성 (고유한 식별자)
- Job Queue에 추가 (선입선출 방식)
- Job Server에서 작업 가져오기
- Worker에서 작업 처리 (오류가 발생하면 Job Server에 오류 발생 사실을 알림)
- 작업 완료 및 결과 처리
- 작업 실패 처리
💡 작업하면 좋은 종류
이메일 발송 (대량), 데이터 처리 및 분석 작업, 파일 변환, 외부 API 호출, 주기적인 작업 (일정 주기로 반복해야하는 작업)
✅ 전문검색서비스
사용자가 입력한 텍스트로 검색하면 가장 관련성이 높은 결과를 보여주는 서비스
검색하려는 키워드가 여러 개면 원하는 검색 결과를 얻기 어렵다는 점을 개선하기 위해 나온 서비스
- ElasticSearch, Apache Solr, Mysql과 PostgreSQL Full Text Search
💡 동작방식 - 인덱스 생성 단계
- 텍스트 데이터 수집 - 텍스트를 추출하고 정규화
- 토큰화 - 텍스트를 토큰으로 분리
- man running in the mountains ->
man,running,in,the,mountains - 아버지가 방에 들어가신다 ->
아버지,가,방,에,들어가,신다
- man running in the mountains ->
- 불용어 제거 및 어근 추출 - 검색에 불필요한 단어를 제거하고, 단어를 기본형이나 어근으로 변환
- 코끼리들 ->
코끼리 - 먹었습니다 ->
먹
- 코끼리들 ->
- 인덱스 구축
💡 동작방식 - 검색 쿼리 처리 단계
- 쿼리 분석 - 사용자가 입력한 검색 쿼리를 토큰화, 어근 추출
- 인덱스 검색 - 토큰에 대해 인덱스를 조회하여 토큰이 포함된 문서 검색
- 순위 매기기 - 검색 쿼리와 일치하는 문서들을 찾아서 관련성 점수 계산
- 결과 반환 - 순위가 매겨진 문서 목록을 반환
✅ 클라우드 기반 인프라
💡 인프라 구성요소
- 서버 하드웨어 - 물리적 또는 가상의 서버
- 네트워크 장비 - 라우터, 스위치 등 네트워크를 최적화하는 장비
- 저장 장치운영 체제 및 서버 소프트웨어
- 데이터베이스 시스템
- 모니터링 시스템
- 보안 시스템
- 백업 및 재해 복구 시스템
네이버나 카카오와 같은 회사들을 제외하고는 아마존, 구글 클라우드를 사용하여 인프라를 구축함
💡 인프라 서비스 모델
- IaaS (Infrastructure as a Service)
- 서버, 스토리지, 네트워킹과 같은 기본 컴퓨팅 인프라 제공
- 필요에 따라 리소스를 추가/제거할 수 있음
- 사용한만큼만 비용을 지불
- 사용자가 운영체제부터 DB, 응용프로그램까지 제어 가능 (관리에 전문지식이 필요)
- AWS, Microsoft Azure, Google Cloud
- PasS (Platform as a Service)
- 애플리케이션을 개발하고 배포하기 위한 플랫폼
- 인프라 설정에 소요되는 시간을 줄일 수 있음 (빠른 서비스 제공 가능)
- Heroku, Google App Engine, Vercel, Netlify
- SaaS (Software as a Service)
- 인터넷을 통해 제공되는 소프트웨어 애플리케이션
- 가입만 하면 사용할 수 있음
- 개인정보 보호에 대한 우려가 있음
- Slack, Google Workspace, Microsoft 365
✅ 보안
💡 네트워크보안
네트워크 상에서의 침입이나 공격을 방어하는 것
특정 아이피에 대해 접근을 허용하거나 차단할 수도 있음
- 방어방법: 방화벽 (Security Group, WAF), 침입 탐지 시스템, SSL 프로토콜 사용 (암호화)
💡 데이터 보안
데이터베이스에 저장된 데이터에 대한 보안
- 방어방법: 데이터 암호화 (비밀번호와 같은 중요한 정보 암호화하여 저장), 데이터베이스 접근 권한 관리 , SQL Injection 방어
💡 애플리케이션 보안
인증이나 권한 관리 시스템을 구현해서 사용자 데이터를 보호하고 무단 접근으로부터 시스템을 보호
- 방어방법: 인증 (Authentication), 권한 관리(Authorization), CORS (Cross-Origin Resource Sharing), XSS (Cross-Site Scripting) 방어
💡 운영 보안
서비스를 운영하면서 발생할 수 있는 위협에 대한 감시
- 방어방법: 로깅, 개인 정보 조회 이력, 보안 패치
💡 물리적 보안
서버와 하드웨어가 위치한 물리적 공간으 ㅣ보안
- 방어방법: IDC 접근 통제, 감시 시스템, 화재나 재난 방지 시스템
✅ 성능 및 확장성
비즈니스 성공에 직접적인 영향을 끼침
💡 성능 문제
- 웹서버의 과부하 - 메모리 사용량을 확인하여 서버 증설
- 데이터베이스 응답지연 - DB 하드웨어 업그레이드 (비용이 크기때문에 최후의 방법으로 사용), DB 튜닝, 캐싱
- 웹브라우저의 로딩 지연 - CPU 확인, 이미지 압축, 비동기 로딩, 무한 루프
- 해외 접속 지연 - CDN 도입
💡 확장성
사용자 수의 증가나 데이터 양의 증가에 맞춰 적절히 대응할 수 있는 능력
- 수직적 확장 (Scale Up) - 더 강력한 하드웨어로 변경
- 수평적 확장 (Scale Out) - 서버를 추가하여 처리 능력 확장
💡 데이터베이스 확장
- 테이블 분산 - 테이블을 여러 대의 DB에 분산
- DB 복제 - primary-replicate db로 구성됨
- 샤딩(Sharding) - 수평적 확장 가능, 데이터를 조각내 분산 저장하는 데이터 처리 기법
4. 프론트엔드와 백엔드 연동을 위한 핵심요소
✅ HTTP (hyperText Transfer Protocol)
통신 규약, 네트워크 장치 간에 정보를 전송하도록 설계된 애플리케이션 계층 프로토콜
- 클라이언트-서버 구조
- 무상태 (Stateless) - 클라이언트의 상태를 저장하지 않음
- 비연결성 (Connectionless) - 요청을 주고 받을 때만 연결을 유지
💡 쿠키
사용자의 웹 브라우저에 저장된 작은 데이터 조각
주로 사용자의 정보를 저장하기 위해 사용
- 세션관리, 개인화, 추적
✅ API
서로 다른 소프트웨어가 통신하기 위해 따라야하는 규칙
💡 REST API
URL를 사용해 리소르를 명시하고 POST, GET, PUT, DELETE와 같은 HTTP 메소드를 통해 리소스를 처리
- Resource (자원) - 정보의 핵심 단위
- Verb (행위) - 리로스에 수행하려는 작업
- Representation (표현) - 클라이언트와 서버 간에 전송되는 구체적인 데이터 형태 (json, xml)
장점: 단순성, 유연성과 확장성, stateless, 다양한 플랫폼 및 언어
단점: 과도한 데이터 전송, 복잡한 쿼리의 어려움, 표준 부재
💡 GraphQL API
단일한 엔드 포인트에 쿼리를 하여 필요한 데이터만 요청하는 방식
데이터 요청량을 줄임
장점: 데이터 요청의 유연성, 전송량 감소, 단일 엔드포인트, 강력한 스키마, 자동 문서화
단점: 학습 곡선, 캐싱의 복잡성, 쿼리 복잡성, 보안 문제
💡 SOAP
Simple Object Access Protocol의 약자
XML 기반 메세지 사용하여 데이터를 전송하는 표준 프로토콜
장점: 다양한 보안 기능, 확장 가능한 설계
단점: 다른 프로토콜에 비해 복잡함, 성능이 떨어짐
✅ 데이터 교환 형식
💡 JSON
간단하고 가벼운 텍스트 기반 데이터 교환 포맷
다양한 프로그램에서 처리할 수 있음
웹 기반 통신에서 가장 많이 사용되는 포맷
장점: 간결성, 프로그래밍 언어 독립적 (다양한 프로그램에서 사용할 수 있음), 구조화된 데이터 표현
단점: 기능 부족, 데이터 크기
1
2
3
4
5
{
"bookstore": {
"books": [{ "title": "도서1" }, { "title": "도서2" }]
}
}
💡 XML
HTML과 비슷한 텍스트 기반의 마크업 언어
트리형태의 계층 구조를 가짐
장점: self-descriptive(데이터 구조와 의미를 명확하게 하는 태그를 사용), 확장성, 다양한 플랫폼 지원, 유효성 검사
단점: 복잡성, 처리속도, 가독성, 네트워크 효율성
1
2
3
4
5
<?xml version="1.0" encoding="UTF-8"?>
<bookstore xmlns:xsi="http://" xsi:schemaLocation="bookstore.xsd">
<book><title>도서1</title></book>
<book><title>도서2</title></book>
</bookstore>
✅ AJAX
비동기적으로 서버와 통신함으로써 웹 페이지 전체를 다시 로딩하지 않고 웹 페이지 일부만 업데이트할 수 있게 해주는 기술
장점: 웹 페이지 속도 향상, 향상된 사용자 경험, 서버 부하 감소
단점: 보안 취약점, 브라우저 호환성 (대부분의 브라우저에서 지원을 하지만 구형 브라우저에서는 동작하지 않을 수 없음), SEO 문제 (검색엔진이 크롤링을 하지 못함), 디버깅 어려움
✅ 실시간 데이터 처리
웹에서 실시간으로 데이터를 처리하는 기술, 사용자와 실시간으로 상호작용
💡 Server Push
서버에서 클라이언트에게 데이터 스트림을 푸시 방식으로 전송
- 필요할 때만 클라이언트에게 데이터를 전달
- 오래된 브라우저에서는 서버 푸시 기능을 제대로 작동하지 않을 수 있음
- webSocket (채팅과 같은 서비스 사용할 때 사용), sse (단방향 통신, 주식 정보를 받을 때 주로 사용)
💡 Client Pulling
클라이언트가 서버에 주기적으로 요청을 보내 새로운 데이터가 있는지 확인하는 방식
- Ajax Polling (실시간성이 떨어지는 단점), Long Polling (응답을 지연시키는 방식)
✅ 인증
💡 세션 쿠키
전통적인 인증 방식
- 사용자가 아이디와 비밀번호를 입력하고 서버에 인증 요청
- 서버는 인증에 성공하면 서버에 저장, 메모리에 사용자 정보를 저장
- 세션 쿠키를 사용하여 클라이언트에 반환
장점: 호환성, 보안, 서버측 제어 (강제로 만료시킬 수 있음), 개인화 (추가적인 정보 제공 가능)
단점: 서버 부하, 확장성 제한, 세션 쿠키 탈취
💡 JWT
인증된 정보를 토큰에 담아서 사용하는 방식
- Header - 토큰의 타입 또는 알고리즘 방식
- Payload - 토큰에서 사용할 정보의 조각인 claim을 담고 있는 json 객체
- 민감한 사용자 정보는 담지 않는 것이 좋음
- iss (토근 발급자), sub (토큰의 주체, 사용자 id), aud (토큰의 수신자), exp (만료시간), iat (발급시간)
- signature - 토큰의 유효성 검증
- 사용자가 아이디와 비밀번호를 입력하고 서버에 인증 요청
- 서버는 인증에 성공하면 토큰을 발급하고, 발급한 토큰을 클라이언트에게 전달
- 클라이언트는 요청할 때마다 header에 token을 담아서 보냄
장점: self-contained (별도의 저장소가 필요하지 않음), 확장성, 효율성, 높은 보안성
단점: 토큰 크기, payload 보안, 토큰 만료 관리
✅ CORS
동일 출처 정책
사용자의 중요 데이터를 보호하고, 악성 사이트의 공격을 방지하기 위해 설계된 기술
💡 origin

이미지 출처: https://docs.tosspayments.com/resources/glossary/cors
https://example.com/에서 접근 가능 여부 확인
| URL | 접근 가능성 | 이유 |
|---|---|---|
| https://example.com/about | 가능 | 프로토콜, 호스트, 포트 모두 일치 |
| http://example.com/about | 불가 | 프로토콜이 다르기 때문에 접근 불가 |
| https://examplee.com/about | 불가 | 호스트명이 다르기 때문에 접근 불가 |
| https://example.com:8080/about | 불가 | 포트가 다르기 때문에 접근 불가 |
응답 헤더에 추가
1
2
3
4
Access-Control-Allow-Origin : 접근 허용 출처
Access-Control-Allow-Methods : GET, POST
Access-Control-Allow-Headers : Content-Type, Authorization
Access-Control-Allow-Credentials : true (자격 증명 허용 여부)